
このページでは、AIアプリがどのように完成していったかの説明やプロセスの紹介をしていきますよ!!
では・・・どうぞ(^^)/
Webアプリ作成までの過程として、大まかに4つの段階に分けることができます。
前半の2つは主に機械学習(AI)を用いた処理
後半の2つがWebアプリの機能として実装した処理となっています。

それでは早速、機械学習のプロセスから説明していきます。
とは言っても、いきなり説明しても分からないと思うので、まずは簡単な例を使ってざっくりと何をしているのか把握してもらえればと思います。
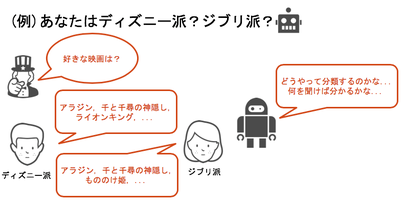
今回の例としては映画の好みとしてディズニー映画派とジブリ映画派とを機械学習で判別させることにします。
ここではまず、「データ収集」として好きな映画を聞いています。
その結果、ディズニー派とジブリ派それぞれの意見がデータとして得られます。それぞれの意見をよく見ると確認できますが、ディズニー派と言ってもジブリ映画は見るようですし、逆も然りであることがデータからわかります。
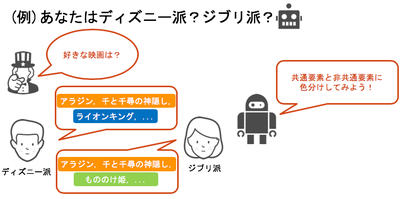
そこで機械学習の処理としては、
派閥間の共通要素と非共通要素とで色分け
つまり分類することにします。
色分けの結果、アラジンと千と千尋の神隠しが共通しており、ライオンキングはディズニー派のみに、もののけ姫はジブリ派のみに見られる非共通な要素であると判明しました。
このようなデータの特徴を抽出する処理を学習と呼んでおり、また学習結果をまとめて整理するまでのプロセスを「モデル構築」と言います。

それでは構築したモデルをもとに、まだどちらの派閥か分からない人がディズニー派なのかジブリ派なのかを予想することにします。
ここで機械学習は以前学習した結果(共通、非共通要素の図)から、アラジンや千と千尋の神隠しのようなどちらにも共通しているものよりも、ライオンキングやもののけ姫のようなどちらかの派閥にしか見られない非共通なものを質問とした方がどちらの派閥かを判別できるのではないかと考えました。

質問の答えとしてライオンキングが選ばれたので、機械学習はモデルからライオンキングがディズニー派にのみ見られる特徴であるという法則性を使い、この人がディズニー派であると予測しました。
結果として今回はうまくいったようです。
(これはあくまで収集したデータから導いた法則であるため、毎度このようにうまくいくとも限りません。)
それではここまでの機械学習プロセスをまとめます。
今回はデータからアラジンやもののけ姫などの特徴を分類することで、それぞれ別の派閥と共通しているか、それとも非共通なものなのかというように、特徴ごとの影響度を学習しています。
そこから非共通要素、つまりライオンキングやもののけ姫などの、特定の派閥にしか見られない重要な特徴を絞り込みました。
このように、各特徴の影響力を求め、その中でも影響力が強く重要と考えられる特徴のみを絞り込むような手法をスパースモデリングと言います。(下記図)
このモデリング手法の特徴としては、そもそも細かな情報を削り落とすためデータ不足に強い、特徴を絞り込んでいるため人間が解釈しやすい、また予測や推薦の処理時間が短いといったメリットがあります。

それではここから実際のプロセスを確認していきたいと思います。かなり遠回りをしましたが、ここまで到達しているならば機械学習の処理がなんとなく理解できると思います。
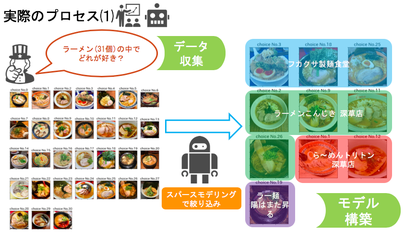
まず「データ収集」では、自分たちで集めた31枚の全国各地ランダムなラーメン画像の中からどれが好きか、そして師団街道のラーメン4つではどれが好きかを聞きました。
そこから「モデル構築」としてスパースモデリングを使用し、31枚の全国各地ランダムなラーメン画像のうち、師団街道の4つのラーメンとの関連性が特に高いものだけを絞り込んだ結果、10枚のラーメン画像のみが残りました。

そしてWebアプリへの実装部分に入っていきます。
Webアプリ内ではトーナメント方式で推薦結果を求めています。
トーナメントの組み合わせは毎回ランダムに決め、「ユーザーによる選択」として師団街道の各ラーメン毎にモデル構築で絞り込んだ関連性の高いラーメン画像をそれぞれ提示し、ユーザーはどちらが好きかを選びます。
選ばれたものは勝ち進んでいき、最終的にトーナメントを勝ち抜いた師団街道のラーメン1つが「モデルから推薦」ということで結果画面に表示されます。このような4段階プロセスによって今回のWebアプリは作成されています。
どうでしたか??
これが、私たちshidanstreetが扱っているAIアプリの制作過程になります!!
また、このページがAI制作をやってみたいという方のお役に立てれば幸いでございますm(__)m